




Notebooks

Categories



Cells
Notebook
Premium

BioTuring
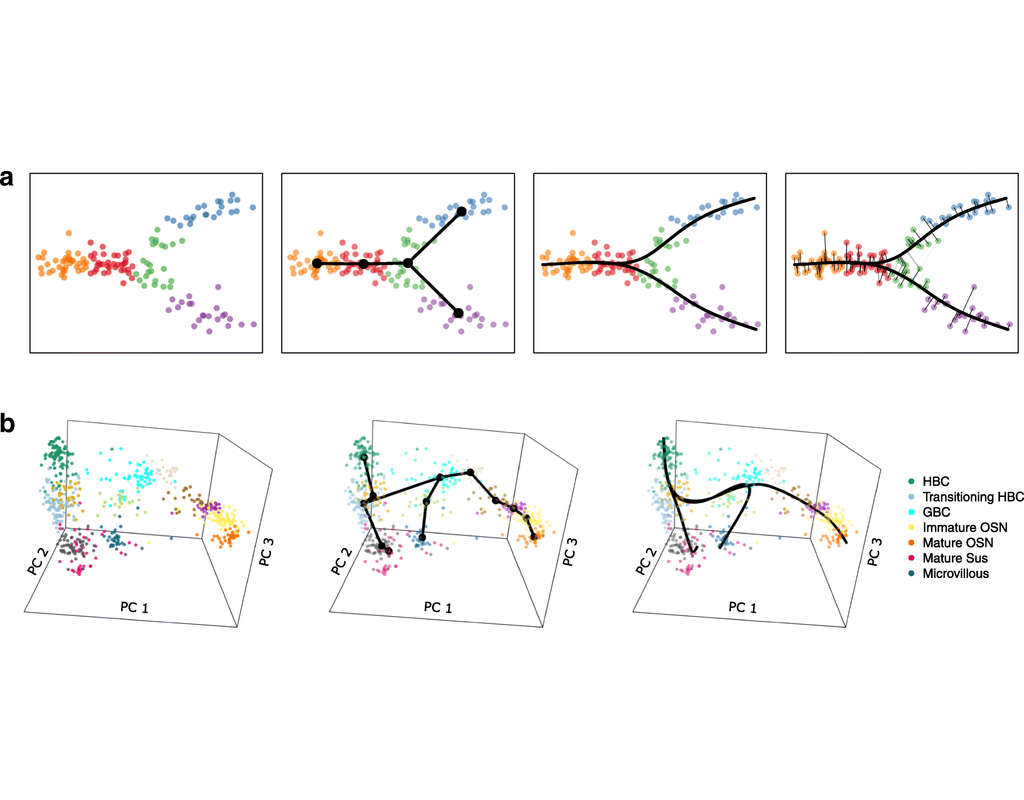
Single-cell RNA sequencing (scRNA-seq) data have allowed us to investigate cellular heterogeneity and the kinetics of a biological process. Some studies need to understand how cells change state, and corresponding genes during the process, but it is challenging to track the cell development in scRNA-seq protocols. Therefore, a variety of statistical and computational methods have been proposed for lineage inference (or pseudotemporal ordering) to reconstruct the states of cells according to the developmental process from the measured snapshot data. Specifically, lineage refers to an ordered transition of cellular states, where individual cells represent points along. pseudotime is a one-dimensional variable representing each cell’s transcriptional progression toward the terminal state.
Slingshot which is one of the methods suggested for lineage reconstruction and pseudotime inference from single-cell gene expression data. In this notebook, we will illustrate an example workflow for cell lineage and pseudotime inference using Slingshot. The notebook is inspired by Slingshot's vignette and modified to demonstrate how the tool works on BioTuring's platform.
BioTuring
Cell2location is a principled Bayesian model that can resolve fine-grained cell types in spatial transcriptomic data and create comprehensive cellular maps of diverse tissues. Cell2location accounts for technical sources of variation and borrows statistical strength across locations, thereby enabling the integration of single cell and spatial transcriptomics with higher sensitivity and resolution than existing tools. This is achieved by estimating which combination of cell types in which cell abundance could have given the mRNA counts in the spatial data, while modelling technical effects (platform/technology effect, contaminating RNA, unexplained variance).
This tutorial shows how to use cell2location method for spatially resolving fine-grained cell types by integrating 10X Visium data with scRNA-seq reference of cell types. Cell2location is a principled Bayesian model that estimates which combination of cell types in which cell abundance could have given the mRNA counts in the spatial data, while modelling technical effects (platform/technology effect, contaminating RNA, unexplained variance).

BioTuring
Advances in multi-omics have led to an explosion of multimodal datasets to address questions from basic biology to translation. While these data provide novel opportunities for discovery, they also pose management and analysis challenges, thus motivating the development of tailored computational solutions. `muon` is a Python framework for multimodal omics.
It introduces multimodal data containers as `MuData` object. The package also provides state of the art methods for multi-omics data integration. `muon` allows the analysis of both unimodal omics and multimodal omics.
BioTuring
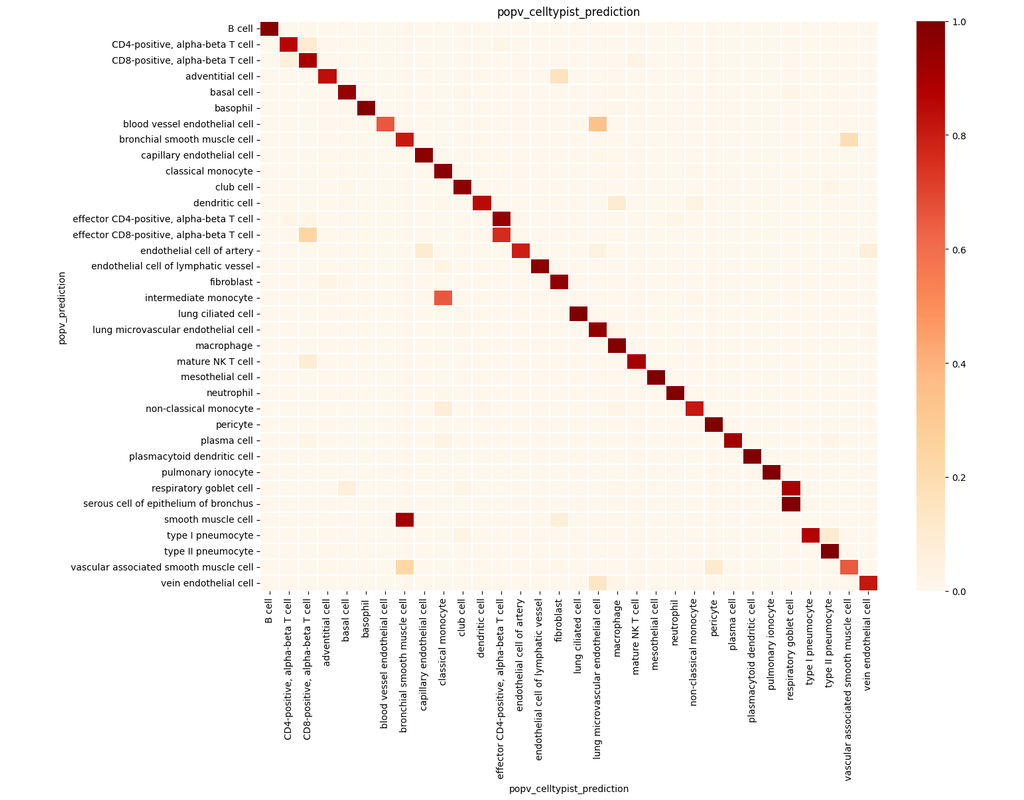
PopV uses popular vote of a variety of cell-type transfer tools to classify cell-types in a query dataset based on a test dataset.
Using this variety of algorithms, they compute the agreement between those algorithms and use this agreement to predict which cell-types have a high likelihood of the same cell-types observed in the reference.