




Notebooks

Categories



Cells
Notebook
Premium


BioTuring
CellRank2 (Weiler et al, 2023) is a powerful framework for studying cellular fate using single-cell RNA sequencing data. It can handle millions of cells and different data types efficiently. This tool can identify cell fate and probabilities across various data sets. It also allows for analyzing transitions over time and uncovering key genes in developmental processes. Additionally, CellRank2 estimates cell-specific transcription and degradation rates, aiding in understanding differentiation trajectories and regulatory mechanisms.
In this notebook, we will use a primary tumor sample of patient T71 from the dataset GSE137804 (Dong R. et al, 2020) as an example. We have performed RNA-velocity analysis and pseudotime calculation on this dataset in scVelo (Bergen et al, 2020) notebook. The output will be then loaded into this CellRank2 notebook for further analysis.
This notebook is based on the tutorial provided on CellRank2 documentation. We have modified the notebook and changed the input data to show how the tool works on BioTuring's platform.

BioTuring
Single-cell RNA-seq datasets in diverse biological and clinical conditions provide great opportunities for the full transcriptional characterization of cell types.
However, the integration of these datasets is challeging as they remain biological and techinical differences. **Harmony** is an algorithm allowing fast, sensitive and accurate single-cell data integration.
BioTuring
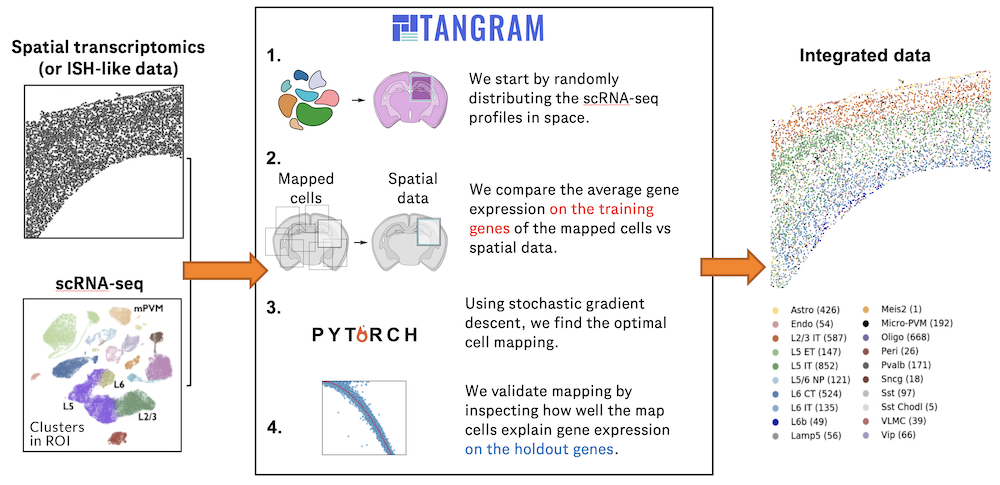
Charting an organs’ biological atlas requires us to spatially resolve the entire single-cell transcriptome, and to relate such cellular features to the anatomical scale. Single-cell and single-nucleus RNA-seq (sc/snRNA-seq) can profile cells comprehensively, but lose spatial information.
Spatial transcriptomics allows for spatial measurements, but at lower resolution and with limited sensitivity. Targeted in situ technologies solve both issues, but are limited in gene throughput. To overcome these limitations we present Tangram, a method that aligns sc/snRNA-seq data to various forms of spatial data collected from the same region, including MERFISH, STARmap, smFISH, Spatial Transcriptomics (Visium) and histological images.
**Tangram** can map any type of sc/snRNA-seq data, including multimodal data such as those from SHARE-seq, which we used to reveal spatial patterns of chromatin accessibility. We demonstrate Tangram on healthy mouse brain tissue, by reconstructing a genome-wide anatomically integrated spatial map at single-cell resolution of the visual and somatomotor areas.

BioTuring
The recent development of experimental methods for measuring chromatin state at single-cell resolution has created a need for computational tools capable of analyzing these datasets. Here we developed Signac, a framework for the analysis of single-cell chromatin data, as an extension of the Seurat R toolkit for single-cell multimodal analysis.
**Signac** enables an end-to-end analysis of single-cell chromatin data, including peak calling, quantification, quality control, dimension reduction, clustering, integration with single-cell gene expression datasets, DNA motif analysis, and interactive visualization.
Furthermore, Signac facilitates the analysis of multimodal single-cell chromatin data, including datasets that co-assay DNA accessibility with gene expression, protein abundance, and mitochondrial genotype. We demonstrate scaling of the Signac framework to datasets containing over 700,000 cells.